install.packages("pak")
pak::pak(c("tidyverse", "webreadr", "summarytools",
"ggside", "scales", "ggnewscale",
"hrbrmstr/iptools", "hrbrmstr/astools"))ggsideによる補足データの表現
はじめに
ggsideというパッケージは、メインプロットの脇に補助的なプロットを表示させるものです。百聞は一見に如かずで、ウェブサイトに掲載されているサンプルを引用しましょう。
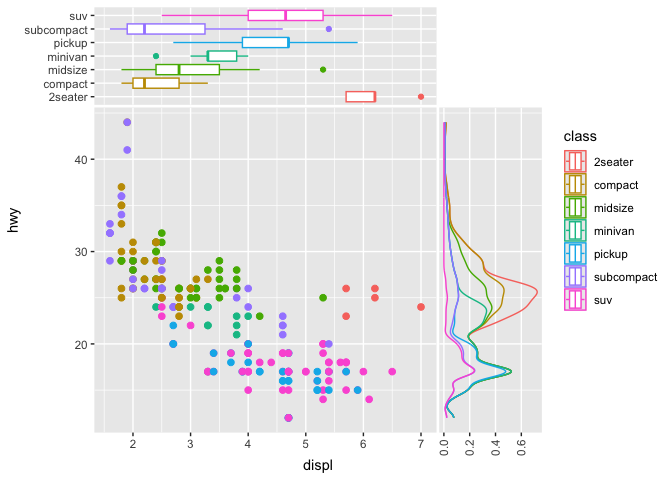
この図では、X軸サブプロット(メインの上)には箱ひげ図(geom_xsideboxplot)が、Y軸サブプロット(メインの右)には密度図(geom_ysidedensity)が載せられています。
ggsideで表現できる図形のうち、GeomTileとGeomTextとを組み合わせると、補足データを数値で表現できるのではないかと考え、実践してみました。具体的には、下の図を作ることを目指します。

データセット
実際のログを使うことができないので、Kaggleの Web Server Access Logsを使います。これはイランのECサイトZanbilのNginxアクセスログで、約3.3GBあります。以下では、このファイルをdata/access.logに格納したと仮定して話を展開します。
再現したい方は、Kaggleからファイルをダウンロードしてください。
必要なパッケージ
いつものTidyverseに加え、7つのパッケージを使います。
webreadr は readrの拡張で、Apache Combinedのフィールド名が最初から定義されています。
SummaryToolsは、記述統計を一括して出力してくれる探索的データ分析(EDA)支援ツールです。
ggsideは先述の通りです。 scalesは、軸や凡例などの尺度を制御するパッケージです。またggnewscaleは、メインプロットと独立したスケールを与えるために使用します。
iptoolsと astoolsとは、このログのIPアドレスを拡張してAS番号を付与するために使用します。iptoolsの後継としてipaddressパッケージがありますが、astoolsがiptoolsに依存しているので、今回は使用しません。
視覚化の目星を付ける
ログファイルを読み込みます。
library(tidyverse, webreadr)
log_df <- webreadr::read_combined("data/access.log")初見なので、簡単に眺めましょう。
glimpse(log_df)Rows: 10,365,152
Columns: 9
$ ip_address <chr> "54.36.149.41", "31.56.96.51", "31.56.96.51", "40.77…
$ remote_user_ident <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ local_user_ident <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ timestamp <dttm> 2019-01-22 00:26:14, 2019-01-22 00:26:16, 2019-01-2…
$ request <chr> "GET /filter/27|13%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%…
$ status_code <int> 200, 200, 200, 200, 200, 200, 200, 200, 200, 200, 20…
$ bytes_sent <int> 30577, 5667, 5379, 1696, 41483, 2654, 3688, 14776, 3…
$ referer <chr> NA, "https://www.zanbil.ir/m/filter/b113", "https://…
$ user_agent <chr> "Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahr…status_codeが整数値になっているので、文字列型に変換します。(status_codeの平均をとったりはしないでしょう。)また、requestフィールドを分解しておきます。webreadrにも関数がありますが、Tidyverseのseparate_wider_delim()関数で十分でしょう。
そのほか、不要な変数を削除し、変数名を短くします。
log_df |>
mutate(status_code = as.character(status_code)) |>
separate_wider_delim(
request,
delim = " ",
names = c("method", "uri", "version"),
too_few = "align_start",
too_many = "drop"
) |>
rename(
src_ip = ip_address,
status = status_code,
bytes = bytes_sent
) |>
select(-ends_with("ident")
) -> log2_df
glimpse(log2_df)Rows: 10,365,152
Columns: 9
$ src_ip <chr> "54.36.149.41", "31.56.96.51", "31.56.96.51", "40.77.167.12…
$ timestamp <dttm> 2019-01-22 00:26:14, 2019-01-22 00:26:16, 2019-01-22 00:26…
$ method <chr> "GET", "GET", "GET", "GET", "GET", "GET", "GET", "GET", "GE…
$ uri <chr> "/filter/27|13%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3…
$ version <chr> "HTTP/1.1", "HTTP/1.1", "HTTP/1.1", "HTTP/1.1", "HTTP/1.1",…
$ status <chr> "200", "200", "200", "200", "200", "200", "200", "200", "20…
$ bytes <int> 30577, 5667, 5379, 1696, 41483, 2654, 3688, 14776, 34277, 1…
$ referer <chr> NA, "https://www.zanbil.ir/m/filter/b113", "https://www.zan…
$ user_agent <chr> "Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com…このログはサイバー攻撃ではないでしょうから、人間の操作に着目します。uriの第一階層をとって、どのような操作があるのかを調べてみましょう。GETよりもPOSTのほうが重要な操作が含まれやすいので、POSTに絞って調べます。
log2_df |>
filter(method == "POST") |>
select(uri) |>
mutate(
uri_top = str_extract(uri, "^/[^/]+")
) |>
1 count(uri_top) |>
arrange(desc(n))- 1
-
count()は、グループ別に 集計できる関数。集計フィールドはデフォルトではnになる。
# A tibble: 227 × 2
uri_top n
<chr> <int>
1 /site 54596
2 /ajaxFilter 31439
3 /orderAdministration 25659
4 /m 12183
5 /comparison 2588
6 /basket 2555
7 /productType 1976
8 /order 1911
9 /j_spring_security_check 808
10 /price 756
# ℹ 217 more rows上から3番目のorderAdministrationというディレクトリが管理操作を彷彿とさせます。下位ディレクトリを見れば、具体的な管理操作が推測できそうです。そこでverbというフィールド名を付けて抽出します。
log2_df |>
filter(method == "POST") |>
filter(str_starts(uri, "/orderAdministration")) |>
mutate(
verb = str_split_i(uri, "/", 3)
) |>
select(timestamp, src_ip, verb, status, bytes) -> log3_df
glimpse(log3_df)Rows: 25,659
Columns: 5
$ timestamp <dttm> 2019-01-22 03:37:12, 2019-01-22 03:37:20, 2019-01-22 03:37:…
$ src_ip <chr> "5.112.217.76", "5.112.217.76", "5.112.217.76", "5.112.217.7…
$ verb <chr> "act", "list", "list", "act", "act", "act", "act_delivery", …
$ status <chr> "200", "200", "200", "200", "200", "200", "302", "302", "302…
$ bytes <int> 9171, 2626, 3582, 12583, 12696, 12986, 0, 0, 0, 12528, 0, 12…このあたりで、各フィールドの全体感をつかんでおきます。それにはdfSummary()が便利です。実務的にはRStudioで別ウィンドウで開くのが最善ですが、ここではhtmlファイルに落とす必要上、テキスト化して表示させています。
Data Frame Summary
log3_df
Dimensions: 25659 x 5
Duplicates: 175
--------------------------------------------------------------------------------------------------------------------
No Variable Stats / Values Freqs (% of Valid) Graph Valid Missing
---- ------------- ------------------------------ ----------------------- --------------------- ---------- ---------
1 timestamp min : 2019-01-22 03:37:12 23212 distinct values : 25659 0
[POSIXct, med : 2019-01-24 05:24:35 . : (100.0%) (0.0%)
POSIXt] max : 2019-01-26 16:57:46 : : . :
range : 4d 13H 20M 34S : : . : :
: . : : : . . . :
2 src_ip 1. 151.239.241.163 10653 (41.5%) IIIIIIII 25659 0
[character] 2. 91.99.30.32 3547 (13.8%) II (100.0%) (0.0%)
3. 91.99.47.57 2698 (10.5%) II
4. 5.78.190.233 2495 ( 9.7%) I
5. 195.181.168.181 631 ( 2.5%)
6. 195.181.169.141 521 ( 2.0%)
7. 104.222.32.84 515 ( 2.0%)
8. 104.222.32.91 485 ( 1.9%)
9. 134.19.177.23 430 ( 1.7%)
10. 2.176.138.136 398 ( 1.6%)
[ 42 others ] 3286 (12.8%) II
3 verb 1. list 9762 (38.0%) IIIIIII 25659 0
[character] 2. act 7270 (28.3%) IIIII (100.0%) (0.0%)
3. producerList 1504 ( 5.9%) I
4. saveActionDescription 1427 ( 5.6%) I
5. saveOrderItemProducer 853 ( 3.3%)
6. editinfoinAdminorder 611 ( 2.4%)
7. notAvailableOrderItemProd 531 ( 2.1%)
8. act_approve 502 ( 2.0%)
9. act_inquiry 463 ( 1.8%)
10. assignToMe 347 ( 1.4%)
[ 32 others ] 2389 ( 9.3%) I
4 status 1. 200 19776 (77.1%) IIIIIIIIIIIIIII 25659 0
[character] 2. 302 5633 (22.0%) IIII (100.0%) (0.0%)
3. 499 163 ( 0.6%)
4. 500 78 ( 0.3%)
5. 502 9 ( 0.0%)
5 bytes Mean (sd) : 4862.9 (5396.4) 5187 distinct values : 25659 0
[integer] min < med < max: : (100.0%) (0.0%)
0 < 2586 < 58575 :
IQR (CV) : 9808.5 (1.1) : .
: . :
--------------------------------------------------------------------------------------------------------------------AS番号を付与する
X軸は時間にするとして、Y軸を何にするか? 私が分析するときには、AS番号を使用することが少なくありません。AS(Autonomous System)とは、インターネットにおいて1組織が管理するネットワークのまとまりです。(1組織が複数のAS番号を保持していることも珍しくない。)
AS番号のデータは生ログには存在しないため、iptoolsとastoolsとを使ってsrc_ipから変換します。
ノート
この文書を作っていて、astoolsの関数の1つであるparse_asnames()が、最新のstringiパッケージの引数に合致しないことが分かりました。いつもAS番号の付与にはSplunkを使っているので、気づいていませんでした。
弥縫策として、名前空間を差し替えて利用可能にします。いずれ作者にプルリクエストを出しておきます。
# astoolsのparse_asnames()がstringiの仕様変更に追い付いていないので、
# 一時的に別名の関数を使って迂回させる。
parse_asnames_fixed <- function(as_fil) {
as_fil <- path.expand(as_fil)
if (!file.exists(as_fil)) stop("File not found.", call. = FALSE)
suppressWarnings(
xdf <- stringi::stri_read_lines(as_fil)
)
xdf <- as.data.frame(
stringi::stri_split_regex(xdf, "[[:space:]]+", 2, simplify = TRUE),
stringsAsFactors = FALSE
)
xdf$iso2c <- stringi::stri_match_last_regex(xdf$V2, ",[[:space:]]+([[:alnum:]]+)$")[, 2]
xdf$V2 <- stringi::stri_replace_last_regex(xdf$V2, ",[[:space:]]+([[:alnum:]]+)$", "")
xdf$handle <- stringi::stri_match_first_regex(xdf$V2, "^[[:upper:][:digit:]-]+")[, 1]
xdf$V2 <- stringi::stri_trim_both(stringi::stri_replace_first_regex(xdf$V2, "^[[:upper:][:digit:]-]+", ""))
xdf$V2 <- stringi::stri_replace_first_regex(xdf$V2, "^[[:space:]]*-[[:space:]]*", "")
xdf$V2 <- stringi::stri_trim_both(xdf$V2)
xdf$V2 <- ifelse(xdf$V2 == "", xdf$handle, xdf$V2)
xdf$V1 <- gsub("^AS", "", xdf$V1)
xdf <- stats::setNames(xdf[, c(1, 4, 2, 3)],
c("asn", "handle", "asinfo", "iso2c"))
class(xdf) <- c("tbl_df", "tbl", "data.frame")
xdf
}
ns <- asNamespace("astools")
unlockBinding("parse_asnames", ns)
assign("parse_asnames", parse_asnames_fixed, envir = ns)
lockBinding("parse_asnames", ns)以下のようにして、IPアドレス(ネットワークアドレス)を元にAS番号を付与します。
rv_df <- astools::routeviews_latest()
1rv_trie <- astools::as_asntrie(rv_df)
2asnames_df <- astools::asnames_current()
log3_df |>
mutate(
asn = iptools::ip_to_asn(rv_trie, src_ip)
) |>
left_join(asnames_df, by = "asn") |>
mutate(
asn_org = str_c(handle, " (AS", asn, ")")
) |>
mutate(
3 asn_org = fct_reorder(asn_org, asn |> as.integer())
) -> log4_df
glimpse(log4_df)- 1
-
as_asntrie()で、データフレームを基数木に変換している。後段のip_to_asn()で、 基数木を引数にとるため。 - 2
-
asnames_current()は、Geoff Huston氏の 「AS6447 BGP Routing Table Analysis Report」からAS名の一覧を 取得している。 - 3
-
asn_orgフィールドは、「IRANCELL-AS (AS44244)」のような文字列。しかし、順序は 名前順ではなくAS番号順にしたいので、fct_reorder()関数を使ってファクター型にしている。
Rows: 25,659
Columns: 10
$ timestamp <dttm> 2019-01-22 03:37:12, 2019-01-22 03:37:20, 2019-01-22 03:37:…
$ src_ip <chr> "5.112.217.76", "5.112.217.76", "5.112.217.76", "5.112.217.7…
$ verb <chr> "act", "list", "list", "act", "act", "act", "act_delivery", …
$ status <chr> "200", "200", "200", "200", "200", "200", "302", "302", "302…
$ bytes <int> 9171, 2626, 3582, 12583, 12696, 12986, 0, 0, 0, 12528, 0, 12…
$ asn <chr> "44244", "44244", "44244", "44244", "44244", "44244", "44244…
$ handle <chr> "IRANCELL-AS", "IRANCELL-AS", "IRANCELL-AS", "IRANCELL-AS", …
$ asinfo <chr> "IRANCELL-AS", "IRANCELL-AS", "IRANCELL-AS", "IRANCELL-AS", …
$ iso2c <chr> "IR", "IR", "IR", "IR", "IR", "IR", "IR", "IR", "IR", "IR", …
$ asn_org <fct> IRANCELL-AS (AS44244), IRANCELL-AS (AS44244), IRANCELL-AS (A…メインプロット
2022年1月に、横軸に時間を、縦軸にAS番号をとって イベントの発生を視覚化する記事を書きました。このとき、geom_point()による散布図で視覚化しています。
今回は、geom_tile()によるヒートマップで視覚化します。ヒートマップを作るときには、一定時間で集計しなくてはいけません。このデータセットの時間幅は4日半ありますので、3時間おきにしましょう。1行あたり34個のタイルで済むはずです。
まず、3時間おきに集計したデータフレームを作成します。
binned_df <-
log4_df |>
mutate(
ts_bin = floor_date(timestamp, unit = "3 hours"),
) |>
count(asn, asn_org, ts_bin, name = "n") |>
mutate(
1 ts_bin = ts_bin + hours(1) + minutes(30)
)- 1
- 3時間を1つの時間幅にしたとき、たとえば0時から3時までを代表する 時刻を1時半とするために、90分足している。こうしておかないと、 たとえば時間軸上にグラフを作ったとき、0時の真上に描画されてしまう。
メインプロットを作図します。ここでscaleパッケージを活用します。
library(scales)
p0 <-
ggplot(binned_df, aes(x = ts_bin, y = asn_org, fill = n)) +
geom_tile() +
scale_x_datetime(
labels = label_date_short(
1 format = c("%Y", "%b", "%d (%a)")
)
) +
2 scale_y_discrete(limits = rev) +
scale_fill_viridis_c(option = "viridis") +
labs(
x = "",
y = "",
fill = "Count",
title = "Requests per ASN (3-hour bins)"
) +
theme_minimal() +
theme(
3 plot.title.position = "plot"
)
p0- 1
-
label_date_short()によって、X軸のラベルが3段で表示できる。 - 2
-
Y軸のラベルの並びは下から上なので(Y座標の数字の通り)、上から下に 昇順で配置するためには、Y軸の並びを反転させる必要がある。ここでは、
limitsオプションにrevというbase関数を渡して実現している。 無名関数で書けばlimits = \(x) rev(x)となる。 - 3
-
plot.title.positionオプションの既定値は「panel」で、メイン プロットの領域を起点としている。より左のY軸ラベルから描画するため、 値を「plot」に変更した。

ひとまずメインプロットは十分でしょう。続いてサイドプロットに移ります。
X軸サイドプロット
X軸サイドプロット(メインプロットの上に描画)は、各時間枠におけるアクセス集の集計を棒グラフで表示させることにします。ヒートマップだと実際の値が分かりませんから、それを補完する役目を与えます。
サイドプロット用にデータフレームを作り、描画を足していきます。
library(ggside)
xside_df <-
binned_df |>
summarise(total = sum(n), .by = ts_bin)
p1 <-
p0 +
geom_xsidecol(
data = xside_df,
aes(x = ts_bin, y = total),
stat = "identity",
1 inherit.aes = FALSE,
fill = "steelblue"
) +
theme(
ggside.panel.scale = 0.6
)
p1- 1
-
inherit.aesオプションは、メインプロットからの美的属性を引き継ぐかどうか。 メインプロットに存在するfillは不要なので、FALSEとしている。

2019年1月25日における管理者画面へのアクセスが少ないですね。イスラム教では金曜日が休日(木曜日が半ドン)ですから、その影響かもしれません。
さて、Countのスケールが右側にありますね。将来こちらにもプロットを配置するので、隙間ができた左上に配置しなおすことにします。カラーバーの向きも横方向のほうが合いそうなので、合わせて修正します。
p2 <-
p1 +
scale_fill_viridis_c(
option = "viridis",
guide = guide_colourbar(
direction = "horizontal",
title.position = "top",
barwidth = unit(3, "cm"),
barheight = unit(0.4, "cm")
)
) +
theme(
legend.position = c(-0.4, 0.95),
legend.justification = c("left", "top"),
legend.background = element_blank(),
legend.margin = margin(t = 2, r = 4, b = 2, l = 4)
)
p2
よくなりました。
Y軸サイドプロット
次にY軸サイドプロット(メインの右)です。こちらにはグラフを置くのではなく、数値を配置してみます。
配置する数値は、
- ASごとのアクセス数の合計
- そのASに含まれるユニークなIPアドレスの数
の2つとしましょう。まずは専用のデータフレームを切り出します。
yside_df <-
log4_df |>
count(asn_org, src_ip, name = "n") |>
summarise(
total_access = sum(n),
unique_ips = n_distinct(src_ip),
.by = asn_org
) |>
1 pivot_longer(
cols = c(total_access, unique_ips),
names_to = "key",
values_to = "value"
) |>
mutate(
key = case_match(
key,
"total_access" ~ "Total\nAccess",
"unique_ips" ~ "Unique\nIPs",
.default = key
)
)
yside_df- 1
- データを縦持ちにして整然データを維持するのがtidyverseの流儀。
# A tibble: 24 × 3
asn_org key value
<fct> <chr> <int>
1 HURRICANE (AS6939) "Total\nAccess" 119
2 HURRICANE (AS6939) "Unique\nIPs" 7
3 M247 (AS9009) "Total\nAccess" 130
4 M247 (AS9009) "Unique\nIPs" 1
5 COLOUP (AS19084) "Total\nAccess" 1695
6 COLOUP (AS19084) "Unique\nIPs" 6
7 NGCS (AS24929) "Total\nAccess" 14
8 NGCS (AS24929) "Unique\nIPs" 1
9 HETZNER-AS (AS24940) "Total\nAccess" 6245
10 HETZNER-AS (AS24940) "Unique\nIPs" 2
# ℹ 14 more rowsこのデータフレームを、Y軸サイドプロットに描画します。
p3 <-
p2 +
1 ggnewscale::new_scale_fill() +
2 geom_ysidetile(
data = yside_df,
aes(x = key, y = asn_org, fill = value),
inherit.aes = FALSE,
show.legend = FALSE
) +
scale_fill_viridis_c(option = "viridis") +
3 geom_ysidetext(
data = yside_df,
aes(x = key, y = asn_org, label = value),
inherit.aes = FALSE,
show.legend = FALSE,
size = 3,
4 color = "white"
) +
theme(
ggside.panel.scale.y = 0.2
)
p3- 1
-
new_scale_fill()でスケールを切り替えないと、メインプロットと同じ尺度で タイルに色分けしてしまう。Total Accessの最大値は1万を超えるから、メインプロットの 色分けが行われなくなる。 - 2
-
geom_ysidetile()でGeomTileを作成。ヒートマップにしたくなければ、fill = valueを 消せばよい。 - 3
-
geom_ysidetext()でGeomTextを配置し、表形式のように数値を表示。 - 4
- 文字色は白色で固定。

おおかた問題ありませんが、AS31549が黄色背景に白文字で、数値が読みづらいですね。残念ながら背景色の彩度に合わせて文字色を切り替える機能はないので、結果を踏まえて、10000以上の数字だと黒色に、そうでなければ白色にします。
p3.1 <-
p2 +
ggnewscale::new_scale_fill() +
geom_ysidetile(
data = yside_df,
aes(x = key, y = asn_org, fill = value),
inherit.aes = FALSE,
show.legend = FALSE,
) +
scale_fill_viridis_c(
option = "viridis",
guide = "none"
) +
ggnewscale::new_scale_color() +
geom_ysidetext(
data = yside_df,
1 aes(x = key, y = asn_org, label = value, color = value > 10000),
inherit.aes = FALSE,
show.legend = FALSE,
size = 3,
) +
2 scale_color_manual(
values = c(`TRUE` = "black", `FALSE` = "white")
) +
theme(
ggside.panel.scale.y = 0.2
)
p3.1- 1
-
colorオプションに真偽値を与えている。 - 2
-
scale_color_manual()関数で、10000超という条件が真のときには黒文字になるよう設定。

これで十分でしょう。
おわりに
ggsideは一見すると2変数の確率分布の周辺分布(一方の変数のみに着目した分布)を図示するのに適したツールです。しかしGeomTextを利用することで、数値を表示させて補足情報を表示することもできます。
今年9月に4.0に到達したggplot2は、一筋縄では飲み込みにくい代物です。ただ、嬉しいことに、LLMが機械的なコードをうまく吐いてくれます。この記事の執筆にも、ChatGPTに助けられました。